Building a Web Crawler with Go to detect duplicate titles
By Flavio Copes
Learn how to build a web crawler in Go that follows links, collects page titles with the golang.org/x/net/html package, and flags duplicate titles for SEO.
In this article I’ll write a small web crawler. I wasn’t sure if my website had nice page titles site-wide, and if I had duplicate titles, so I wrote this small utility to find out.
I’ll start by writing a command that accepts a starting page from the command line, and follows any link that has the original url as a base.
Later I’ll add an optional flag to detect if the site has duplicate titles, something that might be useful for SEO purposes.
A note before we start: a polite crawler should respect the site’s robots.txt rules. If you need to write or test one for your own site, I made a robots.txt generator and tester.
Introducing golang.org/x/net/html
The golang.org/x packages are packages maintained by the Go team, but they are not part of the standard library for various reasons.
Maybe they are too specific, not going to be used by the majority of Go developers. Maybe they are still under development or experimental, so they cannot be included in the stdlib, which must live up to the Go 1.0 promise of no backward incompatible changes - when something goes into the stdlib, it’s “final”.
One of these packages is golang.org/x/net/html.
To install it, execute
go get golang.org/x/net...In this article I’ll use in particular html.Parse() function, and the html.Node struct:
package html
type Node struct {
Type NodeType
Data string
Attr []Attribute
FirstChild, NextSibling *node
}
type NodeType int32
const (
ErrorNode NodeType = iota
TextNode
DocumentNode
ElementNode
CommentNode
DoctypeNode
)
type Attribute struct {
Key, Val string
}
func Parse(r io.Reader) (*Node, error)List the site links and page titles
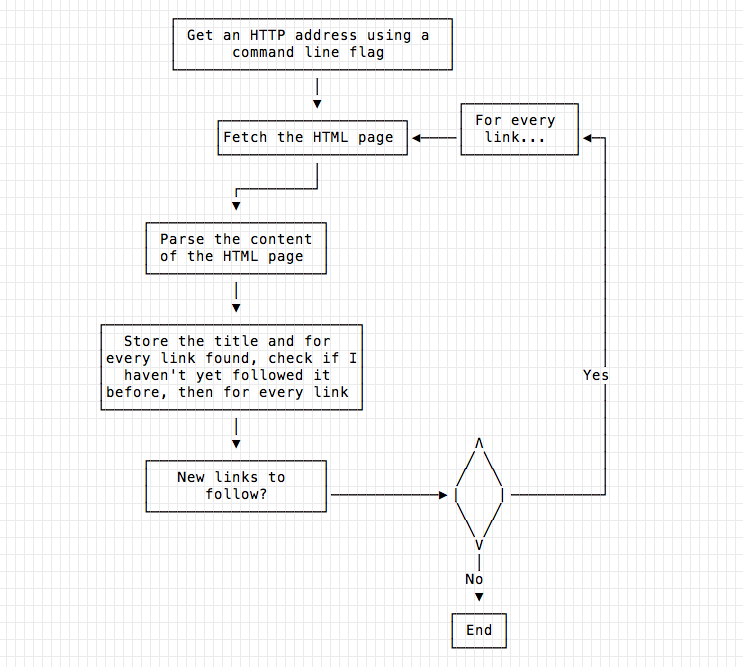
The first program here below accepts a URL and computes the unique links it finds, giving an output like this:
http://localhost:1313/go-filesystem-structure/ -> Filesystem Structure of a Go project
http://localhost:1313/golang-measure-time/ -> Measuring execution time in a Go program
http://localhost:1313/go-tutorial-fortune/ -> Go CLI tutorial: fortune clone
http://localhost:1313/go-tutorial-lolcat/ -> Build a Command Line app with Go: lolcatLet’s start from main(), as it shows a high level overview of what the program does.
- gets the
urlfrom the CLI args using `os.Args[1] - instantiates
visited, a map with key strings and value string, where we’ll store the URL and the title of the site pages - calls
analyze().urlis passed 2 times, as the function is recursive and the second parameter serves as the base URL for the recursive calls - iterates over the
visitedmap, which was passed by reference toanalyze()and now has all the values filled, so we can print them
package main
import (
"fmt"
"net/http"
"os"
"strings"
"golang.org/x/net/html"
)
func main() {
url := os.Args[1]
if url == "" {
fmt.Println("Usage: `webcrawler <url>`")
os.Exit(1)
}
visited := map[string]string{}
analyze(url, url, &visited)
for k, v := range visited {
fmt.Printf("%s -> %s\n", k, v)
}
}Simple enough? Let’s get inside analyze(). First thing, it calls parse(), which given a string pointing to a URL will fetch and parse it returning an html.Node pointer, and an error.
func parse(url string) (*html.Node, error)
After checking for success, analyze() fetches the page title using pageTitle(), which given a reference to a html.Node, scans it until it finds the title tag, and then it returns its value.
func pageTitle(n *html.Node) string
Once we have the page title, we can add it to the visited map.
Next, we get all the page links by calling pageLinks(), which given the starting page node, it will recursively scan all the page nodes and will return a list of unique links found (no duplicates).
func pageLinks(links []string, n *html.Node) []string
Once we got the links slice, we iterate over them, and we do a little check: if visited does not yet contain the page it means we didn’t visit it yet, and the link must have baseurl as prefix. If those 2 assertions are confirmed, we can call analyze() with the link url.
// analyze given a url and a basurl, recoursively scans the page
// following all the links and fills the `visited` map
func analyze(url, baseurl string, visited *map[string]string) {
page, err := parse(url)
if err != nil {
fmt.Printf("Error getting page %s %s\n", url, err)
return
}
title := pageTitle(page)
(*visited)[url] = title
//recursively find links
links := pageLinks(nil, page)
for _, link := range links {
if (*visited)[link] == "" && strings.HasPrefix(link, baseurl) {
analyze(link, baseurl, visited)
}
}
}pageTitle() uses the golang.org/x/net/html APIs we introduced above. At the first iteration, n is the <html> node. We’re looking for the title tag. The first iteration never satisfies this, so we go and loop over the first child of <html> first, and its siblings later, and we call pageTitle() recursively passing the new node.
Eventually we’ll get to the <title> tag: an html.Node instance with Type equal to html.ElementNode (see above) and Data equal to title, and we return its content by accessing its FirstChild.Data property
// pageTitle given a reference to a html.Node, scans it until it
// finds the title tag, and returns its value
func pageTitle(n *html.Node) string {
var title string
if n.Type == html.ElementNode && n.Data == "title" {
return n.FirstChild.Data
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
title = pageTitle(c)
if title != "" {
break
}
}
return title
}pageLinks() is not much different than pageTitle(), except that it does not stop when it finds the first item, but looks up every link, so we must pass the links slice as a parameter for this recursive function. Links are discovered by checking the html.Node has html.ElementNode Type, Data must be a and also they must have an Attr with Key href, as otherwise it could be an anchor.
// pageLinks will recursively scan a `html.Node` and will return
// a list of links found, with no duplicates
func pageLinks(links []string, n *html.Node) []string {
if n.Type == html.ElementNode && n.Data == "a" {
for _, a := range n.Attr {
if a.Key == "href" {
if !sliceContains(links, a.Val) {
links = append(links, a.Val)
}
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
links = pageLinks(links, c)
}
return links
}sliceContains() is a utility function called by pageLinks() to check uniquiness in the slice.
// sliceContains returns true if `slice` contains `value`
func sliceContains(slice []string, value string) bool {
for _, v := range slice {
if v == value {
return true
}
}
return false
}The last function is parse(). It uses the http stdlib functionality to get the contents of a URL (http.Get()) and then uses the golang.org/x/net/html html.Parse() API to parse the response body from the HTTP request, returning an html.Node reference.
// parse given a string pointing to a URL will fetch and parse it
// returning an html.Node pointer
func parse(url string) (*html.Node, error) {
r, err := http.Get(url)
if err != nil {
return nil, fmt.Errorf("Cannot get page")
}
b, err := html.Parse(r.Body)
if err != nil {
return nil, fmt.Errorf("Cannot parse page")
}
return b, err
}Detect duplicate titles
Since I want to use a command line flag to check for duplicates, I’m going to change slightly how the URL is passed to the program: instead of using os.Args, I’ll pass the URL using a flag too.
This is the modified main() function, with flags parsing before doing the usual work of preparing the analyze() execution and printing of values. In addition, at the end there’s a check for the dup boolean flag, and if true it runs checkDuplicates().
import (
"flag"
//...
)
func main() {
var url string
var dup bool
flag.StringVar(&url, "url", "", "the url to parse")
flag.BoolVar(&dup, "dup", false, "if set, check for duplicates")
flag.Parse()
if url == "" {
flag.PrintDefaults()
os.Exit(1)
}
visited := map[string]string{}
analyze(url, url, &visited)
for link, title := range visited {
fmt.Printf("%s -> %s\n", link, title)
}
if dup {
checkDuplicates(&visited)
}
}checkDuplicates takes the map of url -> titles and iterates on it to build its own uniques map, that this time has the page title as key, so we can check for uniques[title] == "" to determine if a title is already there, and we can access the first page that was entered with that title by printing uniques[title].
// checkDuplicates scans the visited map for pages with duplicate titles
// and writes a report
func checkDuplicates(visited *map[string]string) {
found := false
uniques := map[string]string{}
fmt.Printf("\nChecking duplicates..\n")
for link, title := range *visited {
if uniques[title] == "" {
uniques[title] = link
} else {
found = true
fmt.Printf("Duplicate title \"%s\" in %s but already found in %s\n", title, link, uniques[title])
}
}
if !found {
fmt.Println("No duplicates were found 😇")
}
}Credits
The Go Programming Language book by Donovan and Kernighan uses a web crawler as an example throughout the book, changing it in different chapters to introduce new concepts. The code provided in this article takes inspiration from the book.
Related posts about go: